6. Numerical Optimization#
How in the world does a machine learn?
Answer: numerical optimization.
A machine is programmed to perform a specific task—whether that’s predicting house prices (regression), identifying spam emails (classification), or navigating a robot to vacuum the floor. How do we measure whether it’s actually getting better at these tasks?
The loss function is a mathematical scorekeeper that evaluates how well the machine is performing. When the loss function produces high values, the machine is performing poorly. When the loss function yields low values, the machine is doing well. Ideally, we want the loss function to reach zero—the perfect score where the machine makes no mistakes.
Over many rounds of practice, numerical optimization algorithms guide the machine toward lower and lower loss values (hopefully). Each iteration is like the machine taking another shot, getting feedback on how far off it was, and adjusting its approach for the next attempt.
Admittedly, this explanation glosses over quite a few mathematical details (just about all of the details). The specifics of how numerical optimization works, what different types of loss functions look like, and how machines actually update their internal parameters—those are the mechanics we’ll explore.
Numerical optimization is “the thing” of this course. A good book on numerical optimization is by Nocedal and Wright.
Below are two videos comparing two optimization methods used in neural networks: gradient descent and gradient descent with momentum. The two videos are examples of 1-dimensional and 2-dimensional optimization.
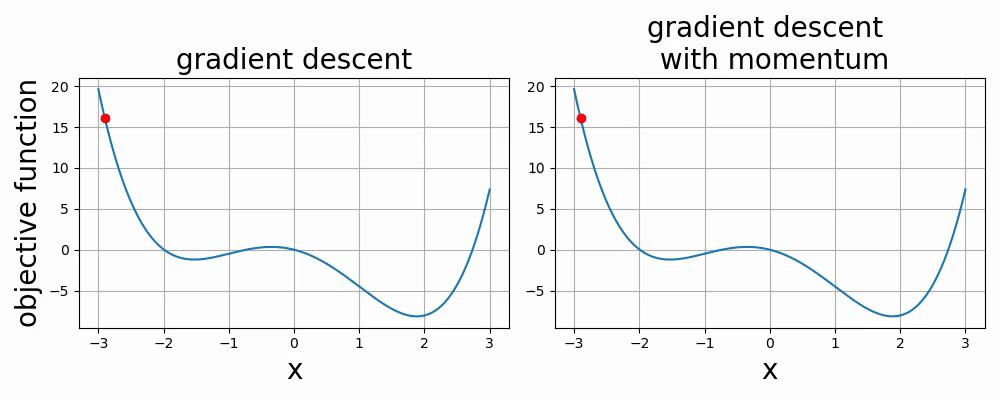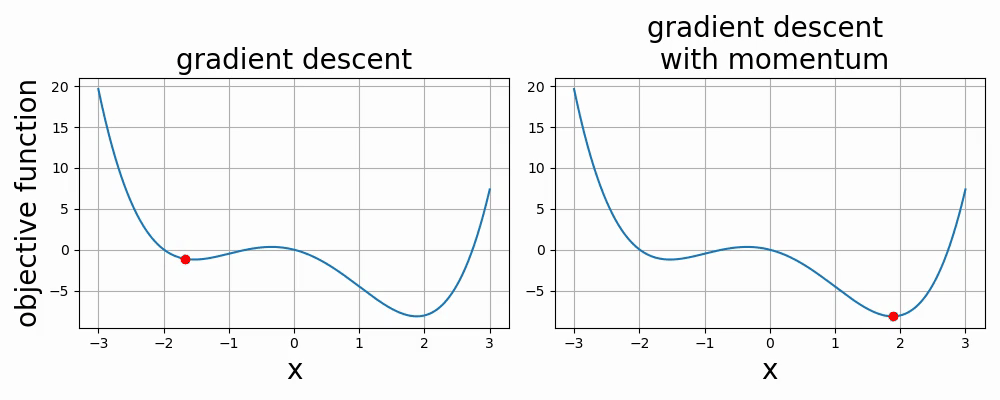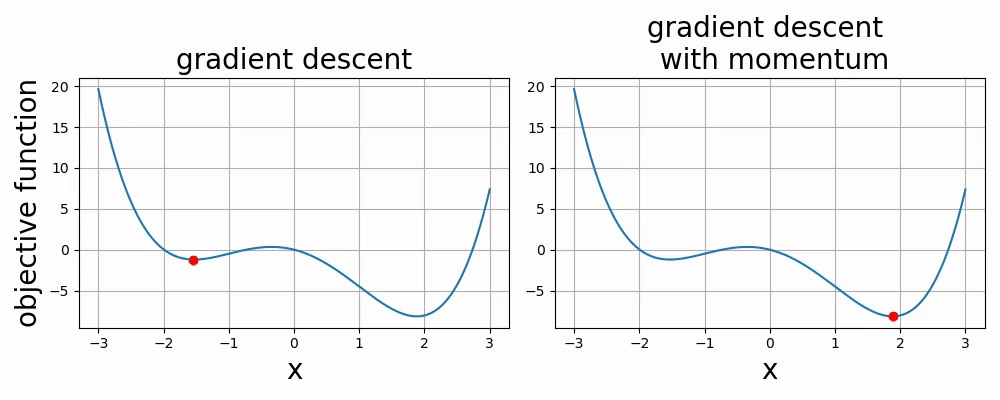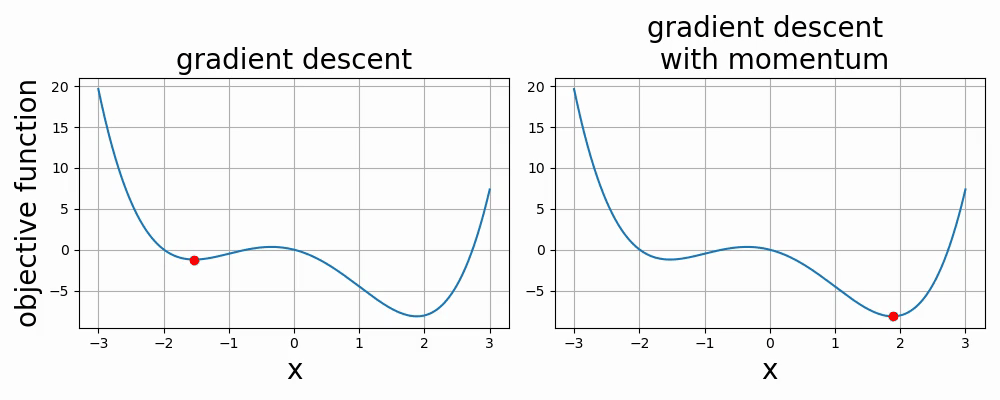
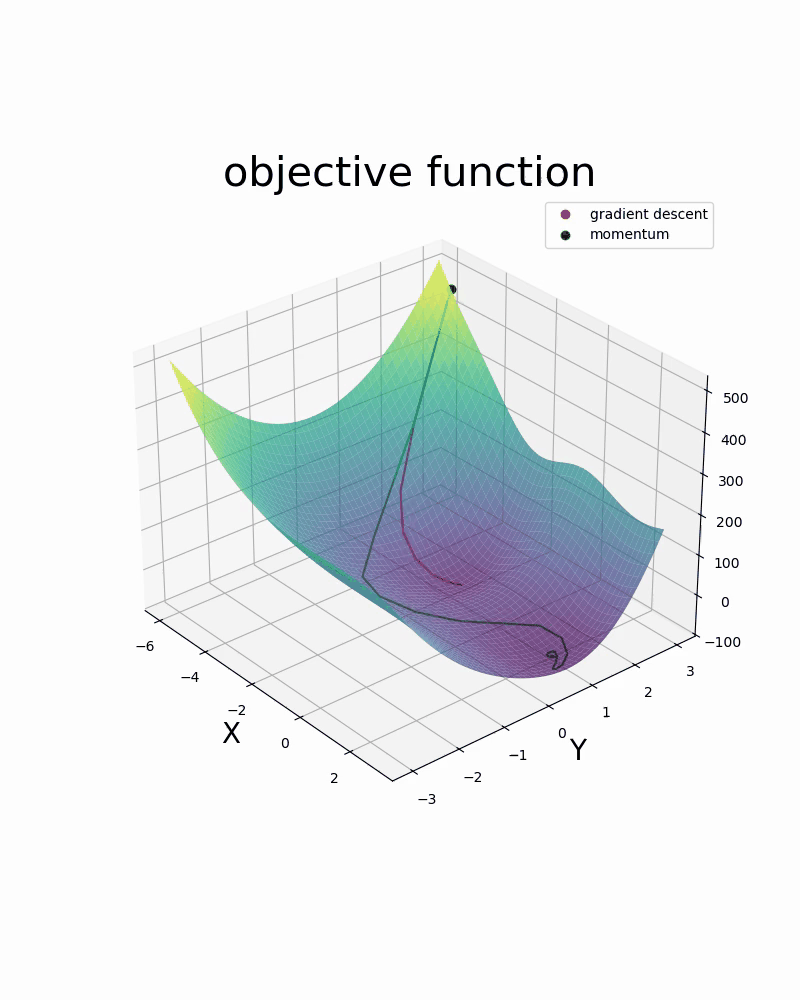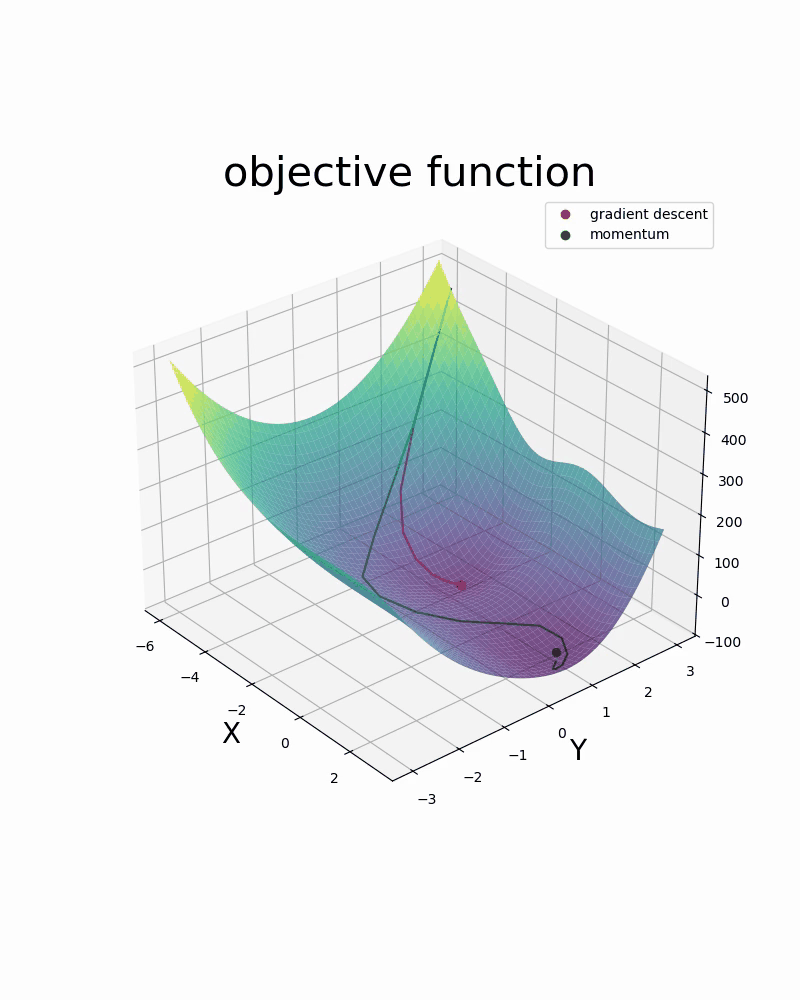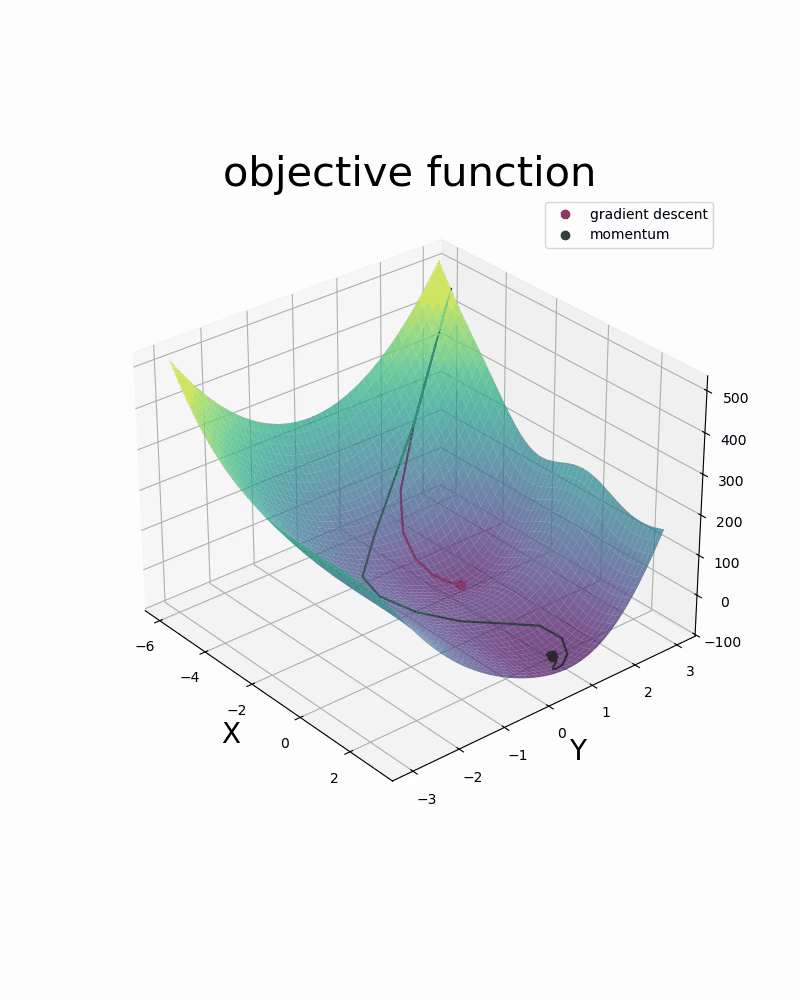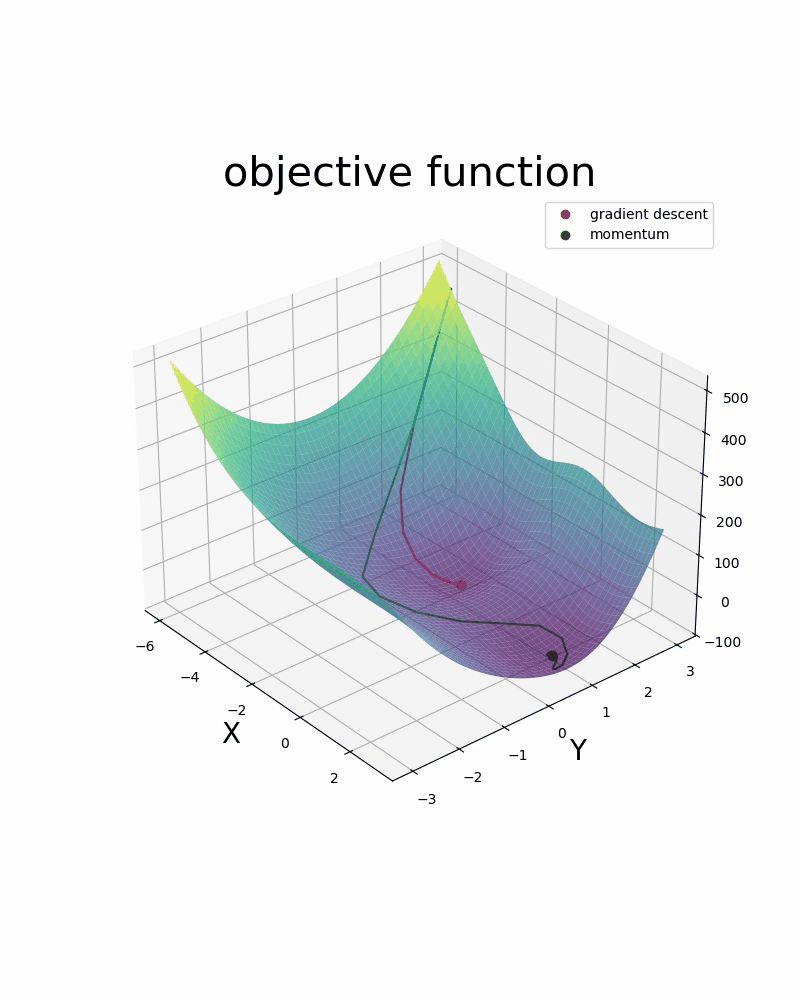
- 6.1. Introduction to Optimization via Linear Regression
- 6.2. Convex Functions and Optimization
- 6.3. The Nelder-Mead Algorithm, Downhill Simplex, or the Amoeba
- 6.4. Particle Swarm and the Eggholder Challenge
- 6.5. Newton’s method for Root Finding
- 6.6. Newton’s Method for Optimization
- 6.7. Logistic Regression with Newton’s Method via Jax (Assignment)
- 6.8. Introduction to Gradient Descent
- 6.9. Gradient Descent in 1-Dimension